
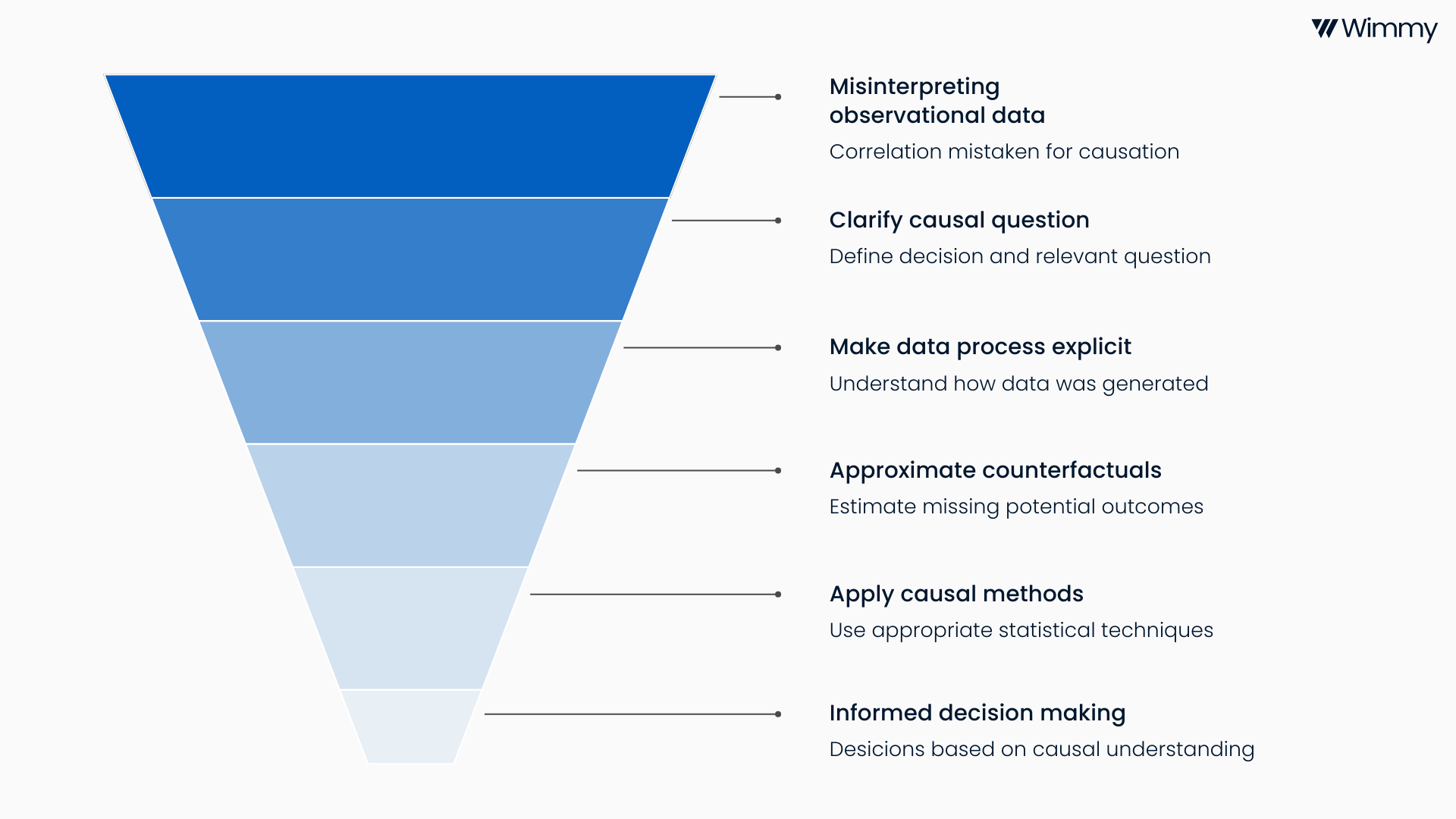
Data is everywhere. Organisations collect vast amounts of data about people, transactions and outcomes. Typically, the data is visualised at face value to get a sense of “the lay of the land”. And almost always the immediate next suite of questions that leaders ask revolves around trends, changes, causes and effects. Yet, an all too common mistake is to confuse correlation with causation. Observational data can tell us what happened, but without the right analysis, it cannot reliably tell us why it happened or what would have happened if we hadn’t intervened. This is where causal inference from observational data comes in.
Causal inference is the discipline concerned with understanding cause and effect. In idealised conditions, for instance, a large experiment with an intervention and a control arm in which participants are randomly assigned to either arm, causal inference methods are straightforward and the bread-and-butter for statisticians. In an ideal world, we would answer every important question with a well designed randomised controlled trial. In reality, most strategic, operational and policy decisions rely on data that was not collected by experimentation, or the experiment did not include a parallel control arm. When you are in the business of providing real-world routine healthcare, the subjects of decisions are patients, doctors, health insurance claims and prescriptions, and it is unethical, impractical and unaffordable to randomly assign them to one of two or more decision arms. It is in this context that causal inference provides a principled way to learn from this data while being explicit about assumptions and uncertainty.
The value of causal inference lies in its focus on decisions. Leaders want to know whether changing one thing will change another and by how much. To what extent a new policy will reduce costs. By how much a programme will improve health outcomes. Descriptive analytics and predictive models are useful, but typically don’t answer causal questions.
The risk of taking observational data at face value is bias. People self-select into programmes. Clinicians treat sicker patients differently. Resources are allocated based on need, history or judgement. These processes create systematic differences between groups that simple comparisons cannot untangle. Naive before-and-after comparisons, uncontrolled regressions or dashboard level trend analysis often produce answers that seem clear but are wrong. Acting on these results can lead to wasted resources, unintended consequences and loss of trust in data-driven decision making.
Causal inference tackles these risks by making the data generating process explicit. It starts with a clear causal question framed in terms of potential outcomes. What would have happened to the same subject under different conditions. Because we can never observe both realities at once, causal methods attempt to approximate this missing so-called counterfactual as credibly as possible using the available data and assumptions.
There is a rich toolbox of methods designed for different contexts. Matching and propensity score methods aim to balance observed characteristics between treated and untreated groups. Regression adjustment and doubly robust estimators combine modelling approaches to reduce bias. Difference-in-difference methods exploit natural experiments over time. Instrumental variables leverage external sources of variation to address unmeasured confounding. More recent approaches such as target trial emulation and machine learning based causal estimators help analysts reason clearly about assumptions and scale analysis to complex, high dimensional data.
None of these methods are magic. They all rely on assumptions that must be stated, tested where possible and communicated clearly. Good causal inference is as much about careful thinking, domain knowledge and transparency as it is about statistical techniques and advanced computational methods. When done well, it allows organisations to learn responsibly from real world data and make better decisions under uncertainty.
At Wimmy, this way of thinking is central to how we work. We spend time with clients clarifying the decision they need to make, the causal question that matters and the data generating process behind their data. We combine strong statistical foundations with practical experience in healthcare. The goal is not to produce elegant models for their own sake, but to support decisions that stand up to scrutiny and result in our clients achieving higher levels of efficiency, bigger positive health impact and undeniable proof of value. Causal inference does not remove uncertainty, but it replaces false certainty with informed judgement. In a world increasingly driven by data, that distinction matters.

-6.png)
-5.png)